
Benefits of using kafka and first steps
The traditional approach to store data
Imagine that you have an application that writes in the database every time that a customer searches/buys a product. The traditional approach is to write synchronously to the database every change that a customer is doing in your application. He selects a product from your catalog and adds it to the shopping cart.
If you are not writing in database and you are changing the information in the session then you are losing information, and every event related with the customer behavior is data that you can use for your online business.
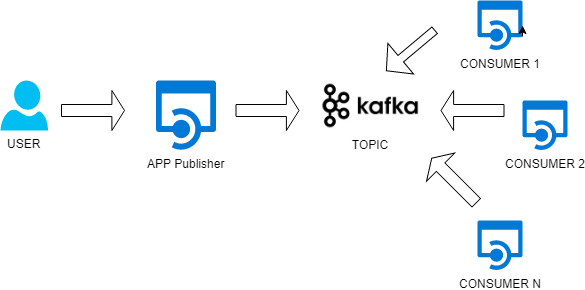
The Pub/Sub pattern
Publish/subscribe messaging is a pattern that is characterized by the sender (publisher) of a piece of data (message) not specifically directing it to a receiver. Instead, the publisher classifies the message somehow, and that receiver (subscriber) subscribes to receive certain classes of messages. Pub/sub systems often have a broker, a central point where messages are published.
Benefits of Kafka
The idea is to move to an event-sourcing-like approach because of the following benefits:
- Loose coupling
By separating the form in which you write and read data, and by explicitly translating from one to the other, you get much looser coupling between different parts of your application.
- Read & write performance
Denormalization (faster reads) exists only because of the assumption that writes and reads use the same schema. If you separate the two, you can have fast writes and fast reads.
- Scalability
They allow you to decompose your application into producers and consumers of streams
- Flexibility
The ways in which you want to present data to users are much more complex, and can be continually changing. If you have an explicit translation process between the source of truth and the caches that you read from, you can experiment with new user interfaces by just building new caches using new logic, running the new system in parallel with the old one, gradually.
- Auditability/error recovery
If you deploy buggy code that writes bad data to a database, you can just re-run it after you fixed the bug and thus correct the outputs. Those things are not possible if your database writes are destructive.
Originated in Linkedin
Kafka was created to address the data pipeline problem at LinkedIn. It was designed to provide a high-performance messaging system that can handle many types of data and provide clean, structured data about user activity and system metrics in real time.
The primary goals were to:
- Decouple producers and consumers by using a push-pull model.
- Provide persistence for message data within the messaging system to allow multiple consumers.
- Optimize for high throughput of messages.
- Allow for horizontal scaling of the system to grow as the data streams grew.
Kafka is Open source
Kafka was released as an open source project on GitHub in late 2010. As it started to gain attention in the open source community, it was proposed and accepted as an Apache Software Foundation incubator project in July of 2011.
Where the name comes from
People often ask how Kafka got its name and if it has anything to do with the application itself. Jay Kreps offered the following insight:
I thought that since Kafka was a system optimized for writing, using a writer’s name would make sense. I had taken a lot of lit classes in college and liked Franz Kafka. Plus the name sounded cool for an open source project. So basically there is not much of a relationship.
First steps with kafka
Download the latest release from here https://kafka.apache.org/downloads
Kafka uses Zookeeper Server then we have to start it first of all.
bin/zookeeper-server-start.sh config/zookeeper.properties
Start kafka server :
bin/kafka-server-start.sh config/server.properties
Create a topic HelloWord :
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic HelloWord
If everything is going well we received a message informing about the new Topic.
Start a kafka console producer :
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic HelloWord
Start a console consumer :
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic HelloWord --from-beginning
Conclusion
Kafka is a streaming platform that helps enterprises to handle real time data feeds in a unified, high-throughput, low-latency way. It allows users to subscribe to it and publish data to any number of systems or real-time applications.
Example applications include managing passenger and driver matching at Uber, providing real-time analytics and predictive maintenance for British Gas’ smart home, and performing numerous real-time services across all of LinkedIn.
Comments